Alan Dix
email: alan@hiraeth.com
download onCue now - it's free!
Full reference:
Alan Dix (1998).
The Active Web - part II.
Interfaces, 39 pp. 22-25.
http://www.hcibook.com/alan/papers/ActiveWeb/aw2.html
See also:
This is the second part of a two part article. In Interfaces 38 we looked at the issues affecting the choice of an appropriate web technology and at the use of basic animation and media. In this part we'll examine several scenarios for adding interactive elements to web pages and for generating and updating web pages from databases.keywords: world-wide web, interaction, design, HCI, CSCW, Java, JavaScript, JDBC, CGI, servlets
In Part I of this article we briefly considered the plethora of technologies available now on the web and some of the critical issues for active web design. From the external, user's viewpoint we need to ask what is changing: media, presentation or actual data; by whom: by the computer automatically , by the author, by the end-user or by another user; and how often, the pace of change: seconds, days or months? From a technical standpoint we need to know where 'computation' is happening: in the user's web-browsing client, in the server, in some other machine or in the human system surrounding it. The 'what happens where' question is the heart of architectural design. It has a major impact on the pace of interaction, both feedback, how fast users see the effects of their own actions, and feedthrough, how fast they see the effects of others' actions. Also, where computation happens influences where data has to be moved to with corresponding effects on download times and on the security of the data.
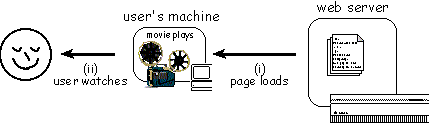
In the first part we looked at the simplest form of active web page, those with movies, animated gifs or streaming video. These are simplest, not in the sense that no effort is required - a short video clip may require many days of production effort - but in the sense that they have least user interaction. In this part we'll look at more complex forms of interaction. First, where the actual content is fixed, but the user can change the form of presentation, secondly at the generation of pages from database content, and finally at the update of database information through the web.
Although the last of these could be considered 'collaborative' at a fairly minimal level, putting real CSCW applications on the web adds an extra level of complexity. I don't have space to cover this here, but if you are interested see the proceedings of the 1996 ERCIM workshop on "CSCW and the Web", last year's CSCW Journal special issue on the subject (reprinted as a Kluwer book) and my own pages on web architecture [2, 1, 4]
Probably the most hyped aspect of the web in recent years has been Java. In fact, Java can be used to write server-end software and platform-independent standalone programs (not to mention the embedded systems for which it was originally designed!), but the aspect that most people think of is Java applets.
In fact, applets are just one of the techniques that can be added to give client-end interaction (and about the least well integrated into the rest of the page). The most common alternatives are JavaScript and VBScript (which are also the power behind Dynamic HTML), but vendor-specific solutions such as Shockwave are also heavily used, and in research systems client-end Tcl/Tk plug-ins are available [7]. These techniques share the characteristic that they are downloaded to the user's own machine and thereafter all interaction happens on the PC, not across the network (with caveats - see below).

The simplest use of this is to add interaction widgets such as roll-over buttons (usually using JavaScript). More complex pages may add the equivalent of an interactive application on the page. For examples, see my own pages on coin-tossing experiments [12], which use JavaScript to emulate real and biased coins, and also my pages on interactive stacking histograms [13], which use a Java applet. See Sun's own sites for many more examples. The addition of DHTML gives even more opportunities for dynamic pages where parts of the page can move, change size, or change content all without any interaction with the web-server.
Notice how this local interaction confuses the static model of the web. What should happen when you go back to a previously visited page, or reload it? Do you get the original state or the last state of your interaction? What happens if you launch a second window on the same page? The actual behaviour tends to be browser specific and not always what you would expect! In particular, some browsers do not re-initialise applets on a reload and so if you edit the applet's parameters and then reload you may not see the effects of your changes. More of a problem for web developers than end-users, but very confusing.
Some user-driven interaction can be accommodated at the client-end, but not all. Consider search engines. It would be foolish to download several megabytes of information so that a Java applet can search it locally! Instead all common web search pages work by submitting forms to the server where CGI programs perform the searches and return results. An additional reason for this approach is that most browsers support forms, but many still do not support Java or scripting in a consistent manner. The search engine for our Human-Computer Interaction textbook web pages works in this way. The user's keywords are submitted to the server using an HTML form, compared against pre-prepared indexes at the server, and all matching paragraphs in the book are returned [10]. This also reminds us of another reason for not downloading all the text to the user's machine: security - we don't want to distribute the full electronic text for free!
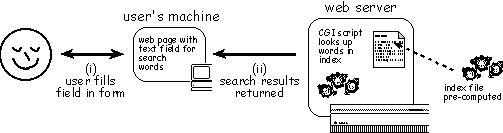
Notice that, in all the above, the underlying content does not change, the variable factor is the user's input. The computation (working out what to show) needs both the data supplied by the web author (pages, databases, indexes, etc.) and the user's input. The result must end up on the user's screen. Either the data must come to the user's machine (as in my dancing histograms where the histogram data is in applet parameters), or the user's input must go to the server (as with the search). We can see from the examples that the choice between these depends on the required pace of interaction, the size of the dataset required, security and available technology.
It was evident in the earliest days of the web that a key problem for the future would be maintenance. In the first rush of enthusiasm individuals and organisations produced extensive and fascinating sites built largely of hand-crafted HTML. Not surprisingly, vast areas of the web are not just static but in perpetual stasis. Web surfing sometimes seems not so much a water-sport, but an exercise in archaeology.
From the beginning it was clear that web sites would eventually need to be created from databases of content combined with some form of template or layout description. However, at that stage there were no tools available and those who saw the database future used a variety of ad hoc methods. Some of my own earliest web material was automatically created from HyperCard stacks or tagged text files and I have supervised projects generating pages using Access, Visual Basic and C. Indeed, these ad hoc approaches are still more flexible and often easier than the vendor-specific solutions.
Happily there are now a (sometimes bewildering) array of products for automating web production from existing and bespoke databases. These include vendor-specific products such as Oracle Web Server, Domino (for publishing Lotus Notes), Cold Fusion and Microsoft's Visual Interdev/ASP; and also more general techniques such as using SQL, ODBC or JDBC to access databases from CGI scripts or even from running Java applets.
There are many advantages of database-generated web sites. They make use of existing data sources. They guarantee consistency of different views of the data within the site and between the site and the corporate data. They allow easy generation of tables of contents, indices, and inter-page links. They separate content and layout. Of course, this separation of content and presentation has been an issue in user-interface architecture for many years, being the driving force behind the Seeheim model, MVC, PAC and the Arch-Slinky model [6, 5, 3, 9]. It is also an issue the web community is embracing with the development of CSS and XML.
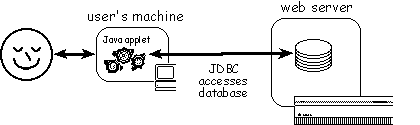
Probably the most high-tech way to get database content on the web is to access a database directly from a running applet. The interface can then have any look-and-feel that can be programmed in Java and can allow very rapid interaction with the user. The Java applet can establish an Internet connection back to the web-server to access data files using HTTP (as if they were web pages), can connect to a bespoke server (e.g. for chat-type applications) or can use the standard database access methods in JDBC. Using JDBC the applet can issue complex SQL queries back to the database meaning that some of the most complicated work happens there.
In all cases, the Java security model built into most web browsers means that the applet can only connect back to the machine from which it came. This means that the database server must run on the same machine as the web-server. Think about this. The most insecure part of any system is usually the web-server, both because it is easy to leave loopholes in the many file access permissions and also because it often sits outside the most secure part of a corporate firewall.
The more common solution is where the user uses a web forms interface (or special URL) and then a CGI script runs at the server end accessing the database. The CGI script generates a web page which is then returned to the user. Some of the vendor-specific solutions use essentially this approach but bypass the web-server/CGI step by having their own special web-server which accesses the database directly using their own scripting language or templates. Similar effects can be obtained using other server technology, such as Microsoft's ASP, Java servlets, and some forms of server-side includes.
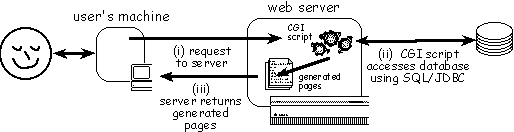
The user interface of such systems is limited to standard HTML features. This is a limitation, but is at least consistent and means that they will work with virtually any browser. Java applets can offer more rapid surface interaction, but both have to wait for the actual data to move between server and client. Of course, the pages generated by a CGI script can themselves contain JavaScript or Java applets for local interaction, so the difference between the two solutions is not so radical as first appears.
From a security angle the database accessed from the CGI script can run on a separate machine (using standard database remote access methods or even a Java/JDBC CGI program), thus making the system more secure. However, the database cannot be entirely secure - if the web-server machine is compromised the CGI scripts can be altered to corrupt or modify the database! The special vendor-specific web-servers are probably more secure as they don't require a standard web-server to be running.

Finally, we have what at first sight appears to be the low-tech solution, the generation of pages off-line from a database. My own early HyperCard solutions were of this form as is HyperAT [8]. This is certainly the simplest solution as it separates out the task of page generation from that of page delivery. Pages can be generated using many standard database packages including PC-based databases such as Access, or Hyper Card, or using programs accessing a database such as Visual Basic, Java or C. These can run on a central computer, or on your own PC. The generating program simply produces a set of HTML pages on your own disk which can be checked locally and then copied onto the web-server using ftp or shared network disks. Many people think that this will be difficult, but in fact it is remarkably easy as you can use the tools you are used to - if you can create a text file you can create HTML. In fact, the snippet of Visual Basic below is a fully functioning HTML generator!
Set db = openDatabase("C:\test.mdb");
sql = "select Name, Address from Personnel;"
Set query = db.OpenRecordset(sql)
Open "out.html" For Output As #1
Print #1, "<h1>Address List</h1>"
query.MoveFirst
While Not query.EOF
Print #1, "<p>" & query("Name") & " "; query("Address")
query.MoveNext
Wend
Close #1
query.Close
|
As well as the ease of programming, the off-line generation of web pages means that there is no need for an on-line connection between the web-server and the database, so a breach in the security of the web-server doesn't compromise your database. In addition, it may mean that the web-server can be configured without CGI scripting enabled at all, which considerably increases its security. Another benefit is that even with very high hit rates the database engines are not overloaded, which results in better performance.
The downside is that you can only show the indices and pages that you can pre-compute. So, you could use a product database to produce a pro-forma page for each stock item, as well as alphabetic and categorised lists, but could not produce a special list based on a user's own search criteria.
As you can probably tell, this low-tech solution is my favoured one in many circumstances - whenever the pace of change is low (e.g. overnight or periodic updates acceptable), the volume of data not too large and no on-line searching is required. Even when some of these conditions don't hold it is possible to use the general approach. For example, searching can often be arranged by having a much cut-down database or index on the web-server with most pages pre-computed. Similarly, on our Intranet in the School of Computing at Staffordshire, we have timetables organised by module, year group, and member of staff, all drawn from a central Oracle database. Whenever the timetable database is updated (via a non-web-based Oracle form) the affected pages are automatically regenerated and file-transferred to the web-server. This means that the timetables are constantly up-to-date, but that the Oracle database is totally secure.
The above mechanisms manage the feedthrough when the database is updated by some non-web means. Perhaps the most 'active' web pages are those where the content of the pages reacts to and is updateable by web users.
If pages are generated from database content using either the Java-applet/JDBC method or the CGI method, the same mechanisms can as easily be used to update as to access the database. The feedback of changes to the user is thus effectively instantaneous - you check for seat availability on the theatre web page, select a seat, enter your credit card details and not only is the seat booked, but you can see it change from free to booked on the web page.
If instead we consider an estate agent's web page, with houses for sale and potential buyers, the situation is rather different. The pace of change is slow, house purchases take place over days, weeks and months. A solution which automatically marked a house as sold would neither be necessary nor desirable! In this case a socio-technical solution using low-tech database generation would likely be sufficient. The web page can have contact telephone number, email address or message form. These (as well as non-web-based queries) come to the estate agent who then makes the decision as to when to mark the house 'sold'. There is a continuous loop between web user and database, but it involves human as well as automatic processes.
The new British HCI Group consultancy and HCI course web pages [11] are slightly more automated, but embody a similar socio-technical style of solution. Web users can fill out a form with details of their courses or consultancy services. This form is processed by a CGI script which generates an HTML page describing the course/service, but does not automatically link this in to the listing pages. Instead, a copy of the details is sent to moderators for the pages who when they are satisfied inform the web administrator who adds the link.
Thanks to Dave Clarke for his helpful comments.
Web research and comment:
Web examples:
Web books I use myself. Lots of O'Reilly titles as they are written assuming a technically competent reader, and normally give a clear and concise treatment.
See also the Part I bibliography and the web version of this article which has active links to technology, examples and a mini-glossary: http://www.hcibook.com/alan/papers/ActiveWeb/