The interactive querying process
Extended Abstract
at time of writing: Staffordshire University
currently: Lancaster University
email: alan@hiraeth.com
download onCue now - it's free!
Full reference:
Alan Dix (1998).
Interactive Querying - locating and discovering information
Second Workshop on Information Retrieval and Human Computer Interaction, Glasgow, 11th September 1998.
http://www.hcibook.com/alan/papers/IQ98/
Read the full paper (Adobe pdf)
See also:
The once distinct technologies of information retrieval, databases and hypertext are converging and overlapping. In addition, a plethora of interactive visualisation techniques have been developed over recent years. This paper will examine the nature of interactive querying and retrieval in order to understand the common features between apparently diverse retrieval techniques and in so doing help to address the needs of the emerging hybrid information repositories.
Traditionally the information retrieval community and database community worked on very different kinds of data and using very different retrieval techniques. IR focused on free text documents with keyword and similarity-based retrieval. Databases focused on structured data with precise formal queries whether expressed in a program-like (e.g. SQL) or tabular (e.g. query by example) fashion. Hypertext retrieval stands opposed to both these approaches with its network structure and directed browsing for retrieval.
However, these barriers have been dissolving, for example, commercial databases now include large text fields with free-text search. The web although starting out as a hypertext is increasingly borrowing traditional IR techniques for search engines as well as pioneering new technologies such as crawlers and recommender systems. In addition, the chaos of the web has lead to a demand for greater structure and semantics. This has been partly satisfied by 'META' tags, but will be extended radically as XML becomes widely used, which will allow database-like queries over published XML document types.
If we are to develop mechanisms for effective query and retrieval from the emerging hybrid information storage systems, then we must understand the similarities in the semantic models of databases, IR and hypertext. Furthermore, we need to understand how these fit into the human process of interactive retrieval.
Some years ago I developed an intelligent database querying system called Query-by-Browsing (QbB). Although aimed at traditional databases, its focus was on the selection and relevance ranking of specific records - far more similar to IR techniques. However, the differences between the two domains were important. In particular, for database retrieval it is important that the retrieved records are not just a useful or suitable set, but they are precisely the right set. This makes it important to be able to feedback not just the selected records, but also the query generated by the system to retrieve them.
QbB is in the process of being redeveloped in order to include different machine learning algorithms, both to improve the interactive style and to extend the kinds of data managed by it. A sound understanding of the interactive retrieval process is thus essential.
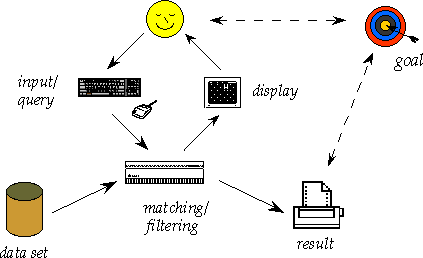
We need to look at the interactive retrieval process at two levels.
First we need to look at the outside picture:
The interactive querying process
Read the full paper (Adobe pdf)
http://www.hcibook.com/alan/papers/IQ98/
| Alan Dix 3/8/98 |